Camera Control for Text-to-Image Generation
via Learning Viewpoint Tokens
Abstract
Current text-to-image models struggle to provide precise camera control using natural language alone. In this work, we present a framework for precise camera control with global scene understanding in text-to-image generation by learning parametric camera tokens. We fine-tune image generation models for viewpoint-conditioned text-to-image generation on a curated dataset that combines 3D-rendered images for geometric supervision and photorealistic augmentations for appearance and background diversity. Qualitative and quantitative experiments demonstrate that our method achieves state-of-the-art accuracy while preserving image quality and prompt fidelity. Unlike prior methods that overfit to object-specific appearance correlations, our viewpoint tokens learn factorized geometric representations that transfer to unseen object categories. Our work shows that text-vision latent spaces can be endowed with explicit 3D camera structure, offering a pathway toward geometrically-aware prompts for text-to-image generation.
Motivation
Controllable image generation with precise camera viewpoint specification is an increasingly important capability for modern generative models. While many text-to-image models have demonstrated remarkable progress in semantic fidelity and visual realism, they struggle to follow even simple geometric instructions such as "back view", "30° left-side view", or "45° top-down perspective." Natural language is expressive but inherently ambiguous and discrete for viewpoint specification, and current models often hallucinate incorrect poses, collapse to biased canonical angles, or produce inconsistent geometry across objects. To overcome these limitations, we introduce a method that augments text prompts with explicit, fine-grained camera control, enabling precise specification of viewpoint.

Our model vs. Gemini 2.5 Flash Image. Our encoded camera viewpoint tokens enable precise, consistent camera pose control, while Gemini 2.5 Flash Image fails despite detailed textual descriptions of camera parameters.
Method
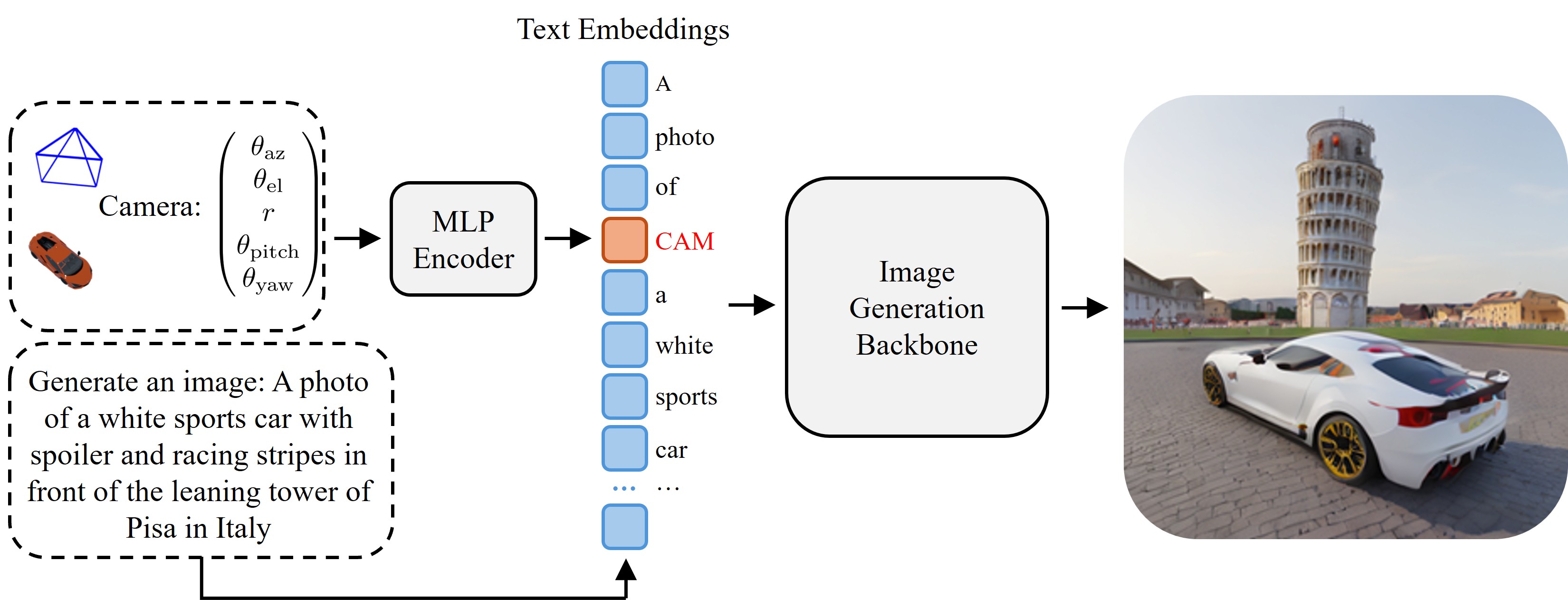
Our method is designed to work with any text-to-image model that operates on text embeddings as inputs. As illustrated above, given a text prompt and explicit camera parameters θ, we generate a parametric viewpoint embedding token in the same input space as the text tokens. The combined text and viewpoint token embeddings are processed jointly through the model to generate viewpoint-conditioned images.
Viewpoint Parameterization. We adopt an object-centric system where the object is fixed at the origin, and the front of the object always faces along the positive x-axis of the world coordinates. This gives us consistent "left/right" and "front/back" in natural language across all objects. We parameterize the camera viewpoint using a factorized 5-parameter representation: azimuth, elevation, radius, pitch, and yaw. Azimuth, elevation, and radius define the camera position in spherical coordinates, while pitch and yaw define the relative camera rotation with respect to the direction from the camera position to the origin. Positive pitch represents camera tilting down, and positive yaw represents camera tilting left.
Qualitative Results
Comparison with baselines on diverse prompts. Our method achieves accurate camera control while preserving high image quality.
| Camera Spec | 3D Render | ControlNet | Novel-View | Compass | Ours |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
| Gundam robot on the streets of Venice | |||||
 |
 |
 |
 |
 |
 |
| Phoenix rising from flames | |||||
 |
 |
 |
 |
 |
 |
| Santa Claus on the streets of Venice | |||||
 |
 |
 |
 |
 |
 |
| Dolphin on still waters | |||||
 |
 |
 |
 |
 |
 |
| Golden retriever in front of the Taj Mahal | |||||
 |
 |
 |
 |
 |
 |
| Fighter jet during sunset | |||||
Results
State-of-the-Art Performance
Our method achieves lower errors than prior methods across all five camera parameters while maintaining high image quality and prompt fidelity.

Strong Generalizability
Our model maintains consistent performance across both "easy" (seen categories) and "diverse" (including unseen categories) test sets, demonstrating robust generalization.

Our method also maintains superior accuracy on challenging back-view and high-elevation configurations.

We preserve the backbone model's prompt alignment ability significantly better than prior methods.

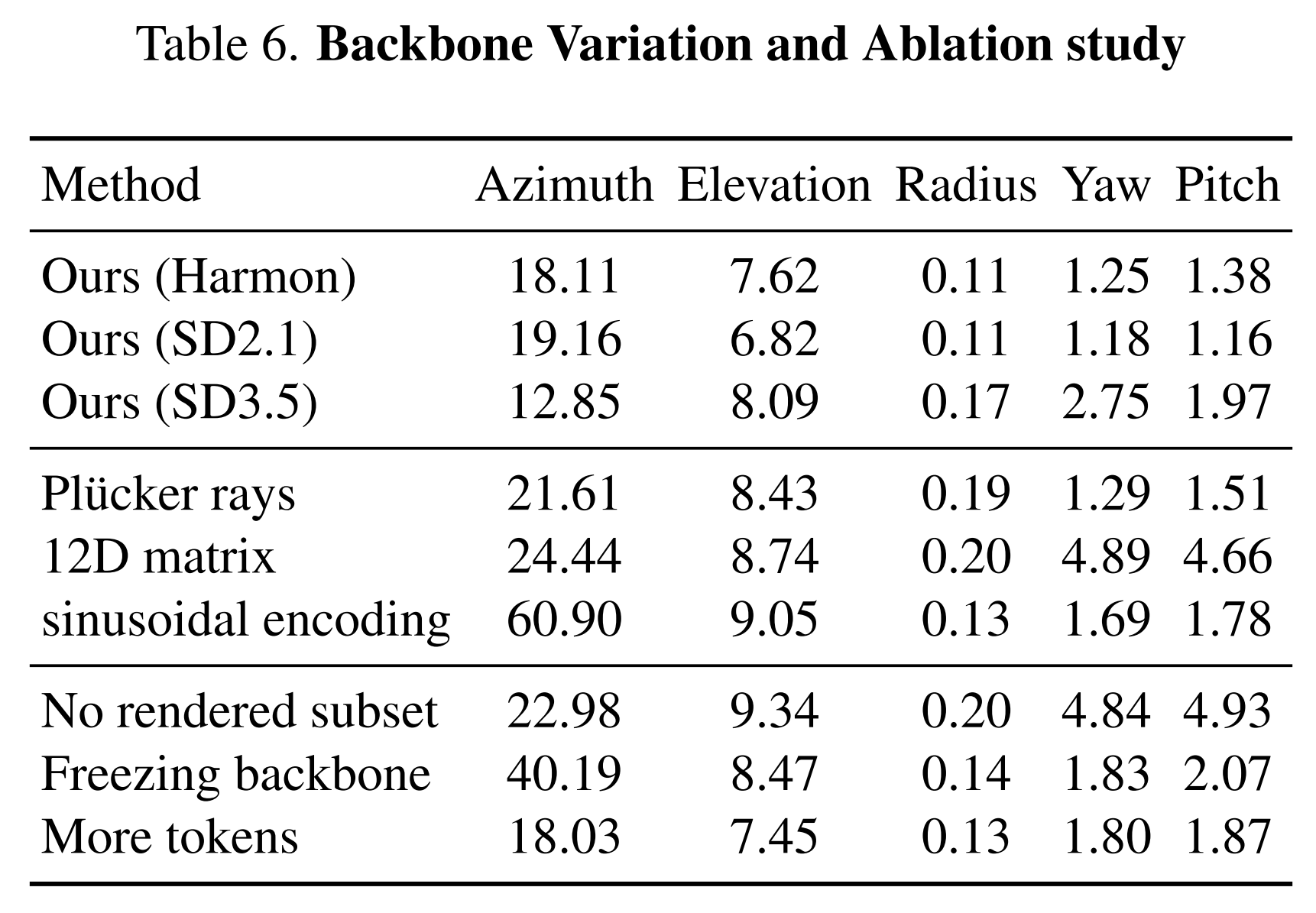
Ablations and Variations
Our method generalizes across backbones (SD 2.1, SD 3.5) and outperforms alternative viewpoint encodings (Plücker rays, 12D camera matrices, sinusoidal). Rendered data and joint LLM+MAR fine-tuning are both essential; extra tokens give no benefit.
Non-Existent Objects
Our model generalizes to objects that do not exist in reality, producing visually plausible and diverse images that faithfully follow both the prompt semantics and the specified viewpoints.
 |
 |
 |
| A small car made of vines and flowers | A flying car with energy ribbon wings | An origami elephant on a wooden desk |
Multi-Viewpoint Generation
Consistent viewpoint control across all five camera parameters. Prompt: "A photo of a white porcelain teapot".
Azimuth and Elevation
| 10° | 55° | 100° | 145° | 190° | 235° | 280° | 325° | |
|---|---|---|---|---|---|---|---|---|
| El 0° |  |
 |
 |
 |
 |
 |
 |
 |
| El 15° |  |
 |
 |
 |
 |
 |
 |
 |
| El 30° |  |
 |
 |
 |
 |
 |
 |
 |
| El 45° |  |
 |
 |
 |
 |
 |
 |
 |
| El 45° (r=6) |  |
 |
 |
 |
 |
 |
 |
 |
Columns: Azimuth (10° to 325°) | Rows: Elevation (0° to 45°) | Main grid uses radius=4.5, bottom row shows radius=6.0
Pitch and Yaw
| Yaw -10° | Yaw 0° | Yaw +10° | Yaw +10° (r=6) | |
|---|---|---|---|---|
| Pitch +10° |  |
 |
 |
 |
| Pitch 0° |  |
 |
 |
 |
| Pitch -10° |  |
 |
 |
 |
| Pitch -10° (r=6) |  |
 |
|
Main 3×3 grid uses radius=4.5 | Extra row and column show radius=6.0 | Fixed azimuth=55°, elevation=15°